Chapter 1 Microcontroller Basics
1. Components of an embedded system
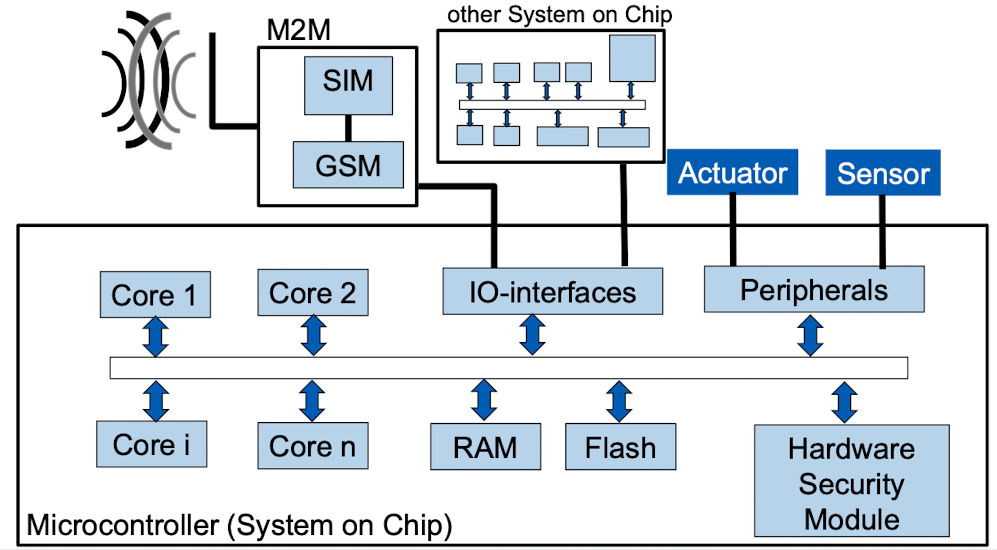
- Processor
- Memory
- I/O Interfaces
- Peripherals
- Hardware Security Module
HSM is a physical device that provides secure storage and processing of sensitive data, such as cryptographic keys and passwords. HSMs are typically used in environments where high levels of security are required, such as in financial institutions and government agencies.
2. Components of a microcontroller

(1) CPU
- Cache/Scratch Pad
- Interrupt Unit
An interrupt unit is a hardware component responsible for managing interrupt requests. An interrupt request is a signal sent by a device or program to the system indicating that it needs to be serviced immediately.
When an interrupt request is received, the interrupt unit temporarily stops the current process and handles the request by injecting a jump to an interrupt handler into the instruction path of the processor.
- Debug Unit
The debug unit is accessed through a debug port or interface. It allows one to view the system’s internal state, including the values of registers, memory locations, and other system variables. It also allows them to set breakpoints and watchpoints, which pause the system’s execution and inspect its state at specific points in time.
- Bus Bridge
A bus bridge is a hardware component that is used to connect buses that operate at different speeds or use different protocols. It allows devices that are connected to one bus to communicate with devices that are connected to another bus.
(2) High Bandwidth Bus
It is typically used to transfer large amounts of data between components in the system, such as between the CPU and main memory, between the CPU and high-speed peripherals, or between DMA and main memory.
- Memory + MMU + MPU
RAM: on-chip volatile memory(erased after power down).
ROM: non-volatile memory.
Flash, EEPROM, FRAM: non-volatile memory but erasable.
- DMA
- Fast IO
PCIe, Ethernet, high-speed USB.
External memory interfaces.
(3) Slow Bus
Peripherals that do not require a high data transfer rate are typically connected to a slow bus, such as:
- Slow I/O
Full-speed USB.
- Accelerators
- AD/DA
- Timer
- Control unit
- MMI(Man Machine Interface)
Interface to displays or keypads.
3. Registers in Cortex-M

(1) Relationship between SP, LR and PC
When a subroutine is called, the current value of the PC is saved in the LR, and the PC is updated to point to the first instruction of the subroutine. At the same time, the SP is typically updated to allocate space on the stack for any local variables or data that the subroutine needs to store.
When the subroutine finishes execution, the program can return to the correct location by loading the value stored in the LR back into the PC. The SP is also typically updated to deallocate the space on the stack that was used by the subroutine.
Why is the link register used to store the return address rather than storing it on the stack?
- Speed
Storing the return address in the LR is faster than storing it on the stack because the LR is a special-purpose register that is dedicated to this purpose and is accessed directly by the processor. Storing the return address on the stack would require additional memory accesses, which would be slower.
- Simplicity
Using an LR to store the return address simplifies the process of calling and returning from subroutines because the return address is always stored in the same place. This makes it easier for the processor to manage subroutine calls and returns and reduces the complexity of the program execution process.
- Efficient use of the stack
Storing the return address on the stack would use up space on the stack, which is needed to store other data, such as local variables and intermediate results.
Why is the return address pushed onto the stack when we have the link register?
- Stack usage
The stack is a data structure that is used to store temporary data, such as local variables and intermediate results. Pushing the return address onto the stack can allow the system to use the link register for other purposes, such as storing temporary data or performing other tasks, without overwriting the return address.
- Function calling conventions
Pushing the return address onto the stack may be required by conventions in order to allow the system to properly return from the function or subroutine.
- Hardware support
Some systems may have hardware support for stack-based function calls and subroutines, which may require the return address to be pushed onto the stack in order to work properly.
4. ARM Assembler Instructions

5. Stack and Heap
(1) Role of Stack
The stack is a data structure that is used to store temporary data. It is called a stack because it operates using the Last In, First Out (LIFO) principle.
- Storing local variables of a function.
- Implementing function calls and returns
Storing the state of the CPU including registers, and current PC (into LR) onto the stack.
- Storing function parameters.
(2) Stack Operations
The stack pointer starts at a high memory address and is decremented during the usage of the stack.
PUSH Rx
The stack pointer is decremented by 4 B (a line on stack). Rx is stored in a location where SP points.
POP Rx
Data at the memory address stored in SP are loaded in Rx. The stack pointer is incremented by 4 B.
(3) Stack Frame Pointer
A stack frame pointer (FP), on the other hand, is a register that points to the base of the current function’s stack frame. The stack frame pointer register is used to keep track of the start of the current function’s stack frame and it is typically used to access the function’s local variables and parameters.
Using a separate stack frame pointer in addition to the stack pointer allows for more efficient memory management and faster access to local variables and function call information. For example, with a separate stack frame pointer, the compiler can use fixed offsets from the frame pointer to access local variables, which can be faster than calculating the offsets from the stack pointer. Additionally, having a stack frame pointer can make it easier to debug the program and trace the function call stack.
For example, FP can improve speed if a function uses dynamic allocation on the stack, e.g. due to runtime-sized local objects in C++
(4) Role of Heap
The heap is a region of memory that is used for dynamic memory allocation. It is called a heap because it is typically implemented as a tree-based data structure, with the root node at the top of the heap and the leaf nodes at the bottom.
The heap is used to allocate memory at runtime, rather than at compile time, and is typically used for large blocks of memory that are needed for a long period of time. It is managed by the system’s memory allocator, which is responsible for allocating (malloc, calloc) and deallocating memory as needed.
Chapter 2 Debugging
for( uint8_t i = 42; i >= 0; --i);
This is an endless loop, since for this loop to stop, i must equal to -1, but i is unsigned and will never be -1.
1. Debugging
(1) Methods
- Changing Code -> Heisenbugs
Assertions, print statements, live checking(blinking LED)
Heisenbugs are particularly challenging to debug because they can be difficult to reproduce and may not always exhibit the same behavior. They may appear and disappear seemingly at random, making it difficult to identify the root cause of the problem.
There are several factors that can contribute to the occurrence of Heisenbugs, including:
- Race conditions
Heisenbugs can be caused by race conditions, which occur when two or more threads or processes try to access or modify shared resources at the same time.
- Timing issues
Heisenbugs can also be caused by timing issues, such as when a program relies on the exact timing of certain events or actions.
- Interactions with hardware or other software
Heisenbugs may also be caused by interactions with hardware or other software, such as when a program relies on certain hardware features or behaves differently when running on different operating systems or hardware configurations.
- Debugger
HW or SW debuggers.
(2) HW Debuggers
Debuggers are specialized tools used to identify and fix errors or defects in a computer program or system. They provide a range of features that allow the programmer to execute a program line by line, inspect the values of variables and memory locations, and control the execution of the program. Some common features of debuggers include:
- Halt After Reset
The “halt after reset” feature is a setting in a debugger that determines whether the debugger should automatically pause the execution of the program after a reset event. A reset event is a condition that causes the program or system to restart, such as a power cycle or a hardware reset.
- Breakpoints
Breakpoints allow the programmer to pause the execution of the program at a specific point and examine the state of the system. They can be set at specific lines of code, at certain memory locations, or when a certain function is met.
- Watchpoints (Data Address + Value Trigger)
Watchpoints allow the programmer to specify variables or memory locations that should be monitored as the program executes. The debugger will automatically pause the program whenever the value of a watched variable or memory location is modified.
- Single Stepping
Execute single machine code instructions stepi
Execute single HLL (High-Level Language) statements step
- Trace
Program trace: Shows, which instructions are executed and when …
Data trace: Allows tracing of certain memory contents
Chapter 3 Interrupts & Exceptions
1. Exceptions & Interrupts
Both temporarily suspend the execution of the current program and transfer control to a special routine called handler. There are several key differences:
- Source
Interrupts are typically triggered by external events, such as a hardware device(keyboard) requesting service or a timer expiring.
Exceptions, on the other hand, are typically triggered by errors or exceptional conditions that occur during the execution of the program, such as division by zero or an illegal instruction.
- Number of auguments
Interrupts do not typically have arguments, as they are simply signals to the processor to stop executing the current code and start executing the ISR. Exceptions can have arguments, which are additional pieces of information that are passed to the exception handler along with the exception. These arguments can be used to provide more information about the exception and to help the exception handler determine how to respond to the exception.
2. Interrupt
(1) Interrupt System

- Interrupt Handler
This is a hardware device that receives interrupts from external devices and internal sources and sends them to the processor. The interrupt controller may also prioritize interrupts and determine the order in which they are serviced.
- Interrupt Handler /Service Routine
This is a special routine that is executed when an interrupt occurs. The interrupt handler processes the interrupt and may also communicate with the external device or internal source that triggered the interrupt.
- Vector Table
This is a table that contains the addresses of the interrupt handlers for each type of interrupt. When an interrupt occurs, the processor looks up the address of the corresponding interrupt handler in the interrupt vector table and transfers control to it.
- Context Save
When an interrupt occurs, the CPU typically saves the current values of 8 caller-saved registers(PC, PSR, R0-R3; R12, LR) on the stack.
(2) Interrupt Latency
- Reasons
The delay between an interrupt signal and the execution of the service routine depends on the time to push context to stack, the time for updating the program counter to the service routine, resource conflicts, interrupts with higher priorities, and the longest run time of any multi-cycle non-interruptable instruction.
- Measures to reduce latency
Tail Chaining: if a 2nd same or lower priority interrupt arrives during the execution phase of 1st, the 2nd interrupt will be executed immediately after the 1st without 1st‘s unstacking.
Late Arrival: if a 2nd higher priority interrupt arrives during the stacking phase of 1st, the 2nd interrupt will be executed first.
Pop Preemption: if a 2nd interrupt arrives during the unstacking phase of 1st, unstacking will be stopped and the 2nd interrupt will be executed immediately.
(3) Types of Interrupts
- Level triggered
The peripheral raises the interrupt signal to the interrupt controller. The SW needs to clear the interrupt bit in the peripheral.
- Edge triggered
The peripheral generates a pulse of a defined length if an interrupt has occurred. The interrupt event has to be stored in the interrupt controller – If the interrupt is executed the interrupt controller clears the flag.
(3) Applications
Wakeup from sleep/power down mode
Timer Interrupts
Handling of communication peripherals
Handling of coprocessors with long runtimes
Direct Memory Access (DMA)
3. Polling
Polling involves repeatedly checking for the occurrence of an event. It might consume a significant amount of CPU time and have higher latency.
4. Exceptions
(1) Types
- Fault
A fault is an exceptional condition that occurs when the program attempts to perform an illegal operation or access memory that it is not allowed to access. Faults are typically handled by the operating system or the processor, which may fix the problem and restart the program.
- Trap
A trap interrupts the normal flow of execution of a program and transfers control to a specific routine or handler. Traps are often used to handle exceptional conditions, such as divide-by-zero errors or illegal memory accesses, and can be triggered by certain events or conditions.
- Abort
Abort terminates a program or process due to an error or exceptional condition. When a program aborts, it stops running and any resources that it was using are released.
(2) Usage
Debugging of programming errors
Scheduling in operating systems
Switching between processor modes
Reconfiguring MPU/MMU settings
5. CMSIS (Cortex Microcontroller Software Interface Standard)
Cortex Microcontroller Software Interface Standard (CMSIS) is a software development framework for microcontrollers based on the Cortex-M processor core. It is developed and maintained by ARM and is intended to simplify and standardize the software interface to the Cortex-M processor core and its peripherals.
CMSIS-Core provides a hardware abstraction layer (HAL): a set of common components, such as device headers, peripheral register definitions, and core peripheral functions that can be used across different Cortex-M-based microcontroller vendors and devices. This allows for a consistent and standardized way of accessing the hardware resources of a Cortex-M microcontroller, regardless of the specific device or vendor. -> Standardization.
The CMSIS also provides a set of libraries, such as CMSIS-DSP and CMSIS-RTOS, which provide a set of standard functions for digital signal processing and real-time operating systems, respectively. This allows developers to write portable and reusable code that can be easily ported between different Cortex-M microcontrollers and development boards. -> Reusability, Faster software development.

- Startup File
startup_<device>.scontains
The reset handler that is executed after CPU reset and typically calls SystemInit (defined in system_.c). The setup values for the Main Stack Pointer (MSP). Exception vectors with weak functions that implement default routines. Interrupt vectors that are device specific with weak functions that implement default routines.
- System Configuration File
system_<device>.ccontains
C functions that help to configure the system properly.
- Device Header File
<device>.hcontains
Definitions related to the specific chip, e.g. base addresses of the peripherals, interrupt numbers (the lower, the higher the priority is)
Chapter 4 Boundary Errors and Control Hijacking Attacks
1. Stack-based Buffer Overflow Attack
C compilers usually arrange the memory as follows:

A typical (function calls other functions) stack frame looks like this

why should stack frame contain the address of the previous frame?
In many computer programs, the call stack is implemented as a linked list, with each stack frame containing a pointer to the previous stack frame. This allows the program to easily access the data associated with the previous function call when a function returns. This is especially important in programs that make frequent use of recursive function calls, as each recursive call creates a new stack frame that needs to be linked to the previous one.
In addition, including a pointer to the previous stack frame in each stack frame can also make it easier to debug the program by providing a record of the sequence of function calls that led to a particular point in the program’s execution. This can be useful in identifying errors or problems in the program’s code.
2. Code Reuse Attacks
- Return-Oriented Programming

The return address can be any RET-like instruction (e.g. pop PC)
- Methodology
1. Scan common libraries for useful instruction sequences ending in gadget chaining instructions (e.g. ret)
2. Chain instruction sequences using RET instructions in order to form the desired gadgets.
3. Create a payload list of the addresses of the gadgets and any
values used for computations.
4. Introduce the payload into the stack.
5. Point the Stack Pointer into the first address of the payload.
3. Countermeasures
- NX segments
Non eXecutable (NX) segments prevent the execution of (injected) code from data segments (e.g. stack)
- Canaries
The program is terminated if the canary in the stack is corrupted and does not match an expected value.
- Shadow Stacks
When a function is entered the return address is copied to a different location called the shadow stack.
4. Other types of Buffer Overflows
- Integer Overflows
Integer overflow occurs when a program tries to store a number that is too large to fit within the allocated space for it. In programming languages, integers are usually stored in a fixed number of bits, such as 8 bits for a byte or 32 bits for a word. When an integer value exceeds the maximum value that can be represented by the allocated number of bits, an integer overflow occurs.
For example, consider a program that uses 8-bit integers to store a count of the number of items in a list. If the program tries to store a value greater than 255 (the maximum value that can be represented by an 8-bit integer), an integer overflow will occur. The value stored in the integer will “wrap around” to a lower value, resulting in incorrect data being stored in the program.
Consequences of integer overflow can include:
Incorrect results: If an integer overflow causes a program to store an incorrect value, this can lead to incorrect results being produced by the program.
Security vulnerabilities: Integer overflows can also create security vulnerabilities in a program. For example, if an attacker is able to cause an integer overflow in a program that is used to check the validity of user input, they may be able to bypass security checks and gain unauthorized access to a system.
- Format String Vunerabilities
#include <stdio.h>
int main(int argc, char *argv[]) {
char username[128];
printf("Enter your username: ");
scanf("%s", username);
printf("Welcome, %s!\n", username);
return 0;
}An attacker could exploit this vulnerability by entering a special format string as their username, such as “%s%s%s%s%s%s%s%s%s%s” or “%x%x%x%x%x%x%x%x%x%x”. This would cause the printf() function to interpret the format string as a series of placeholders for values, potentially leading to the disclosure of sensitive information or the execution of arbitrary code.
“%s” reads a string, “%x” reads a hex value. “%n” writes the amount of printed characters to a pointer to an integer (which an attacker can control)
To prevent this type of attack, the program should validate the user input and ensure that it does not contain any special characters or code that could be used to manipulate the format string. For example, the program could use the scanf() function to parse the user input and check for invalid characters before passing it to the printf() function.
Chapter 5 Memory
The alignment mechanism ensures that variables larger than one byte can be accessed by hardware through its corresponding halfword, word, and doubleword instructions.
A simple memory system:

1. Locality Principle of Cache
- Types
Temporal locality: This refers to the tendency of a program to access data or instructions that have been recently accessed. By storing recently used data and instructions in cache memory, a system can improve performance by avoiding the need to access main memory or storage.
Spatial locality: This refers to the tendency of a program to access data or instructions that are located near each other in memory. By grouping related data and instructions together in cache memory, a system can improve performance by allowing the CPU to access them in a single cache fetch.
By taking advantage of temporal and spatial locality, cache memory systems can significantly improve the performance of a computer system by reducing the number of times the CPU has to access main memory or storage.
- Cache controller
Cache controller is a hardware component that manages the operation of a cache memory system. The cache controller is responsible for managing the flow of data between the cache memory and main memory or storage, as well as controlling the allocation and replacement of data in the cache.
The cache controller typically works in conjunction with the CPU and main memory to provide high-speed access to frequently used data and instructions. When the CPU needs to access a piece of data or an instruction, it first checks the cache memory to see if it is available. If the data or instruction is present in the cache, the cache controller retrieves it and provides it to the CPU. If the data or instruction is not present in the cache, the cache controller retrieves it from the main memory or storage and stores it in the cache for future use.
The cache controller also manages the allocation and replacement of data in the cache. When the cache is full and a new piece of data needs to be stored, the cache controller must decide which data to evict from the cache to make room for the new data. This is typically done using a cache replacement algorithm, which determines which data is least likely to be used in the near future and evicts it from the cache.
- Pro’s and Con’s
– Caches are an attack target
Side channel attacks on cache timing; Encryption of cache contents is difficult
– Caches cost chip area → chips become more expensive
+ Power consumption can be reduced through caches
+ Performance is increased
2. Memory Access Types & Memory Types in Cortex-M
Here are some examples of memory access types in the ARM Cortex-M architecture:
- Code memory access
This type of access is used to read instructions from code memory, which is typically stored in read-only memory (ROM) or flash memory. Code memory access is typically executed in the instruction pipeline and is used to fetch the next instruction to be executed by the CPU.
- Data memory access
This type of access is used to read from or write to data memory, which is typically stored in random-access memory (RAM). Data memory access is used to access variables, data structures, and other types of data that are used by the program.
- Peripheral memory access
This type of access is used to access memory-mapped hardware peripherals, such as serial ports, timers, or analog-to-digital converters. Peripheral memory access is typically executed using direct memory access (DMA) and is used to transfer data between the peripherals and memory without involving the CPU.
- Special function register (SFR) access
This type of access is used to access special-purpose registers that are used to control the operation of the Cortex-M microcontroller. SFR access is typically used to configure the microcontroller’s operation or to access status information.
Memory types contain Normal, Device, Strongly-ordered, and XN(Execute Never).
- Normal (Code and Data Sections)
The processor can re-order transactions for efficiency or perform speculative reads.
- Device (Peripherals)
The processor preserves transaction order relative to other transactions to the Device or Strongly-ordered memory.
- XN (Peripherals)
The processor prevents instruction access. A fault exception is generated only on the execution of an instruction executed from an XN region.
3. Memory Protection Unit (MPU)
(1) Task of MPU
A memory protection unit (MPU) is a hardware component that is used to control access to memory in a computer system. The MPU is responsible for enforcing memory protection policies, which specify which memory regions can be accessed by which processes or tasks.
MPU is located within the CPU and can only check memory accesses performed by the CPU. MPU doesn’t protect actions by DMA peripherals. That is why you should be careful in granting untrusted code access to peripherals.
The MPU works by dividing the memory of a system into a series of memory regions, each with its own set of access permissions. When a process or task attempts to access a memory location, the MPU checks the access permissions for the region that the memory location belongs to and determines whether the access is allowed. If access is not allowed, the MPU generates an exception or fault, which can be handled by the operating system or other software to prevent unauthorized access from occurring.

- Memory Properties
“Sharable,” “cacheable,” and “bufferable” are terms that are used to describe the behavior of memory in a computer system. These terms are often used in the context of memory-mapped hardware devices, such as peripherals or I/O controllers, and can affect the performance and efficiency of the memory system.
Sharable: Memory that is marked as “sharable” can be accessed by multiple devices or processes at the same time. This can improve the performance of the system by allowing multiple devices or processes to share the same memory resources.
Cacheable: Memory that is marked as “cacheable” can be stored in the CPU cache, which is a high-speed memory system that is used to store frequently accessed data and instructions. Cacheable memory can improve the performance of the system by allowing the CPU to access data and instructions more quickly.
Bufferable: Memory that is marked as “bufferable” can be used as a buffer, which is a temporary storage area used to hold data while it is being transferred between devices or processes. Bufferable memory can improve the performance of the system by allowing data to be transferred more efficiently.
- Cache Properties
“Write through” and “write back” are two different caches write policies that can be used to control how data is written to cache memory in a computer system. These policies can be used with or without the “allocate” feature, which determines whether data is allocated in the cache when it is written.
Write through: In a write through cache, data is written to both the cache and main memory when it is updated. This ensures that the data in main memory is always up-to-date, but it can also result in slower write performance because the data must be written to two different locations.
Write back: In a write back cache, data is only written to the cache when it is updated. The data is then marked as “dirty,” indicating that it has been modified in the cache and needs to be written to main memory. The data is only written to main memory when it is evicted from the cache or when the cache is flushed. This can improve write performance, but it also increases the risk of data loss if the system crashes before the dirty data is written to main memory.
With the “allocate” feature: data is automatically allocated in the cache when it is written. This means that data is written to the cache regardless of whether it is already present in the cache or not.
Without the “allocate” feature: data is only written to the cache if it is already present in the cache. If the data is not present in the cache, it is written directly to main memory and not cached.
(2) Usage of MPU
A task in OS normally needs following memory sections: text section for code, data, bss sections for data, and stack.
A possible MPU setup is:
- One background region for privilege mode (operating system)
- One region for
textandrodata(only r and execute) - One region for
dataandbss(r/w no execute) - One region for task’s stack (r/w but no execute)
- One region for peripherals accessible by this certain task
How to change settings of MPU?
The settings of a memory protection unit (MPU) can typically be changed using software commands or by modifying configuration registers in the MPU hardware.
Here are some general steps that might be used to change the settings of an MPU:
- Determine the MPU configuration
The first step in changing the MPU settings is to determine the current configuration of the MPU, including the number and size of the memory regions, the access permissions for each region, and any other relevant settings. This information can often be obtained by reading configuration registers or by using a software command to query the MPU.
- Modify the MPU configuration
Once you have determined the current MPU configuration, you can modify the settings as needed by writing new values to the appropriate configuration registers or using software commands to change the settings.
How to program the MPU safely?
Before changing MPU settings all old data and instruction accesses
have to be completed. This requires the following instructions:
- DSB
The Data Synchronization Barrier instruction ensures that outstanding memory transactions are complete before subsequent instructions execute.
- ISB
The Instruction Synchronization Barrier ensures that the effect of all completed memory transactions is recognizable by subsequent instructions.
Then the MPU should be disabled.
Then the MPU registers can be changed.
Afterwards enable the MPU.
4. Memory Management
Addresses should be independent of the storage location.
Each process should have an own address space.
=> Virtual Memory splits the physical memory into blocks (pages or segments) and assigns these to processes.


(1) Memory Management Unit
Not all ARMv7 processors have a MMU!
A Memory Management Unit (MMU) is a hardware component that is responsible for mapping virtual addresses to physical addresses in a computer’s memory. The MMU performs a number of important tasks, including:
- Translating virtual addresses to physical addresses
When a program accesses a memory location using a virtual address. The MMU translates this virtual address to a physical address, which is the actual location in memory where the data is stored.
- Implementing virtual memory
The MMU is also responsible for managing virtual memory, which allows a computer to run programs that are larger than the amount of physical memory (RAM) available on the device. When a program accesses a memory location that is not currently in physical memory, the MMU can swap the data in and out of physical memory as needed, using a portion of the hard drive as an “overflow” area for data that does not fit in physical memory.
- Additional bookkeeping with status bits
resident: page is in main memory
dirty: has been modified, secondary memory(hard disk) is not yet updated
referenced: this page has been (recently) accessed
- Handling memory management tasks
The MMU can enforce memory protection and isolation between different programs and processes, and manage the allocation and deallocation of memory resources.
- Handling memory-mapped I/O
The MMU can also be used to map I/O devices into the memory space, allowing programs to access I/O devices as if they were memory locations. This can simplify the process of accessing hardware devices and improve the performance of some types of I/O operations.
(2) Virtual Memory Ststem
A virtual memory system is a memory management technique that allows a computer to run programs that are larger than the amount of physical memory (RAM) available on the device. It does this by temporarily transferring data from RAM to a portion of the hard drive known as the “swap space” or “paging file.”
In a virtual memory system, the computer’s memory is divided into equal-sized blocks called “pages.” The operating system maintains a list of which pages are currently in physical memory and which are stored on the hard drive. When a program accesses a memory location that is not currently in physical memory (page fault), the operating system uses the MMU (Memory Management Unit) to swap the required page of data into physical memory from the hard drive. If the old data is unchanged, just overwrite. If modified, write back to hard disk. This process is known as “paging.” (most common replacement strategy: Least Recently Used)
Virtual memory allows a computer to run multiple programs concurrently and perform more complex tasks than possible with a limited amount of physical memory. However, it can also have a negative impact on performance, as accessing data from the hard drive is slower than accessing data from RAM.

- Page Table
A page table is a data structure used in a virtual memory system to map virtual addresses to physical addresses in a computer’s memory. It is typically implemented as a multi-level data structure that allows the operating system to quickly locate the physical memory address corresponding to a given virtual address.
The page table is typically maintained by the operating system and is used by the MMU (Memory Management Unit) to perform the address translation. It is typically stored in the main memory and is accessed by the MMU whenever a program accesses a memory location.
- Page Base Pointer
The page base pointer is a hardware register that is used in some computer architectures to store the address of the beginning of the page table. This allows the MMU (Memory Management Unit) to quickly access the page table when it needs to perform an address translation.
The MMU uses the page base pointer to locate the page tables stage by stage and then uses the information in the last table to find the physical address corresponding to the virtual address being accessed by the program.
(3) Size of Page Tables
- Large Page

Pro’s:
Fewer page faults: Large pages have more data per page.
Reduced overhead: Large pages require fewer page table entries and less space in the page table, which can reduce the overhead associated with maintaining the page table and improve the overall efficiency of the virtual memory system.
Con’s:
Wasted space: Large pages can result in more wasted space when the program only uses a small portion of the memory covered by the page. This can lead to lower overall memory utilization and increase the amount of swap space needed on the hard drive.
Fragmentation: Large pages can be more prone to fragmentation, as they may be more difficult to allocate in a way that maximizes memory utilization.
- Small Page

Pro’s:
Faster paging: Small pages have fewer data per page.
Improved memory utilization & Reduced fragmentation: Small pages can result in less wasted space and better memory utilization, as the pages can be allocated more precisely to fit the needs of the program.
Con’s:
Increased overhead: Small pages require more page table entries and more space in the page table, which can increase the overhead associated with maintaining the page table and reduce the overall efficiency of the virtual memory system.
Reduced performance: Small pages require more memory accesses to access a given memory location, which can reduce the performance of programs that access a large, contiguous block of memory.
(4) Translation Look Aside Buffer
The translation look aside buffer (TLB) is a type of cache located on the CPU or close to it that is used to speed up the translation of virtual memory addresses to physical addresses in a computer’s main memory.
The TLB is used to store the most recently accessed virtual-to-physical address translations, so that the computer can quickly find the physical address corresponding to a virtual address without having to perform a slower, more resource-intensive translation process. When a program needs to access a particular memory location, the TLB is checked first to see if the translation is already stored there. If it is, the physical address can be retrieved from the TLB and used to access the memory location directly. If the translation is not in the TLB, the computer must perform a slower translation process using the page table.
5. Cache Side Channel Attack: Flush&Reaccess
Cache side channel attacks work by analyzing the access patterns of the cache to infer information about the data being processed by the system. For example, an attacker might measure the time it takes to access different locations in the cache, or monitor the power consumption of the system while it is processing data, to infer the content of the data or the operations being performed on it.


6. Meltdown Attack
Meltdown works by exploiting a design feature of certain processors that allows processes running on the system to access the memory of the operating system and other processes. This feature, known as kernel memory sharing, is intended to improve the performance of the system by allowing processes to access memory more quickly and efficiently. However, Meltdown exploits a flaw in the implementation of this feature to allow an attacker to access sensitive data, such as passwords or cryptographic keys, that is stored in the memory of the system.


probe_array is translated into the same physical address of the kernel array that we want to access. 4096B is the size of a cache line.- Attacker trains the prefetcher with a dedicated program, e.g. a loop
- Attack program suddenly
accesses a byte at a memory address in kernel space → CPU prefetcher fetches the data stored at this address in kernel space into cache.
accesses an array with this byte value (4096*data) as the index. With different values of data, we control different lines of cache.
- Then CPU detects that speculation of prefetcher was wrong, and reverts most actions, but Cache data are not deleted
- Now, the attacker accesses the complete array and measures access time
- The access with the shortest access time corresponds to the read byte value (at location
4096*data + probe_array)
Chapter 6 Security & Crypto Overview
1. Goals
(1) Data Integrity
- Protection from non-authorized and un-noticed modification of data
Measures:
- Rules for allowed/not allowed modification of data.
Who can do what under which conditions with which object
- Granting access and control: e.g. r, w, x
- Isolation: User domain, Sandboxes, Virtual Machines
- Manipulation detection: checksums, dig. watermarks
(1) Message Integrity
- Protection from non-authorized and un-noticed modification of message
Measures:
- Isolation: separate channels
- Manipulation detection: checksums, dig. watermarks
(2) Confidentiality
- Protection from non-authorized information retrieval
Measures:
- Rules for allowed/not allowed information flow.
Who can have access to which information
- Encryption of data
- Information Flow Control through Classification of Objects and Subject
(3) Availability
- Protection from non-authorized interference with the usability or correct function of a system
Measures:
- Determination of thresholds, e.g. avoid overloading
- Obligations for recording and controlling.
which access to which objects is granted when, and how many resources are allocated (e.g. memory)
(4) Authenticity
- proof of the identity of an object/subject
Measures:
- Rules for unique identification of subjects and objects
passwords, keys, biometrics, smartcards
- Methods for proving the correctness of identities
Certificates, Credentials, Token.
Challenge/Response Protocols.
(5) Accountability
- Non-repudiation. Protection from disclaiming that a performed activity was not carried out.
Measures:
- Each action is bounded to the subject performing it: Signature
- Each action and the corresponding time is recorded into log files
- Perform auditing
(6) Privacy
- Protection of personal data and any data regarding the
private sphere to ensure the right of self-determination
Measures:
- Rules for avoidance or minimization of recorded data
- Define the purpose of use
- Data aggregation: k-Anonymity Methods
- Pseudonyms: the identity is known to a Trusted Third Party only
- Non-Traceability: variable Pseudonyms
2. Comparision
- symmetric encryption & MAC
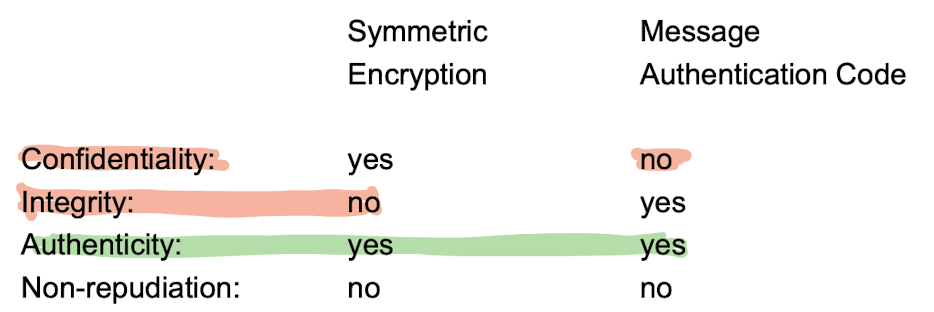
- asymmetric encryption & digital signatures

3. Common Ciphers
- Symmetric Block Ciphers: AES, DES, MAC
- Asymmetric Cryptography: RSA, Signature(DSA)
- Hash Functions: SHA2, SHA256, SHA512
Chapter 7 Memory Protection & Encrypted SW Updates
Memory encryption is the process of encrypting data that is stored in a computer’s internal and external memory. This is done to protect the data from being accessed by unauthorized parties.
Memory encryption is typically implemented at the hardware level, using specialized chips or circuits that are built into the computer’s memory module. These chips or circuits are responsible for encrypting and decrypting the data as it is being written to and read from the memory.
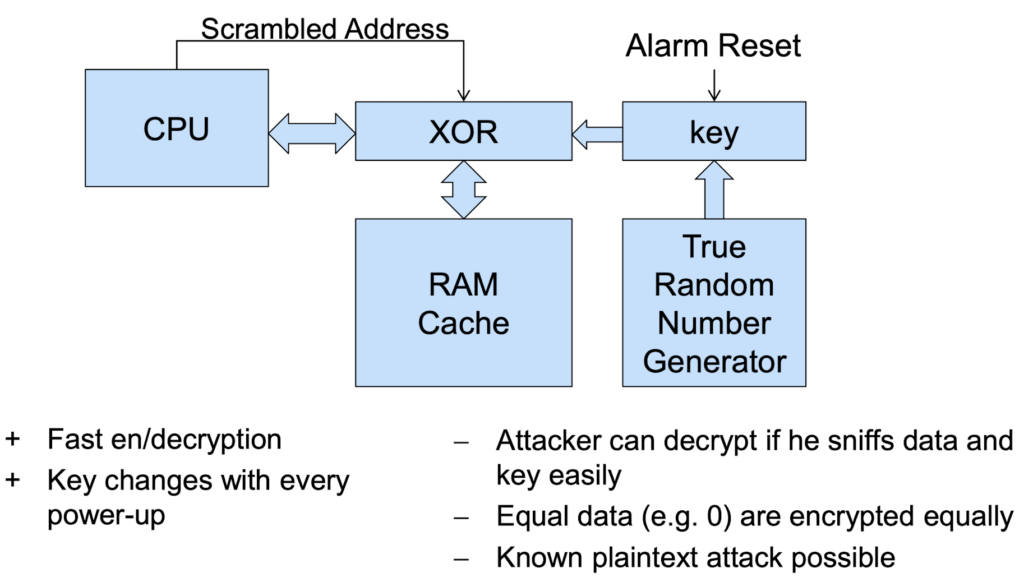
1. Encryption of Internal Memory(RAM)
2. Encryption of External Memory
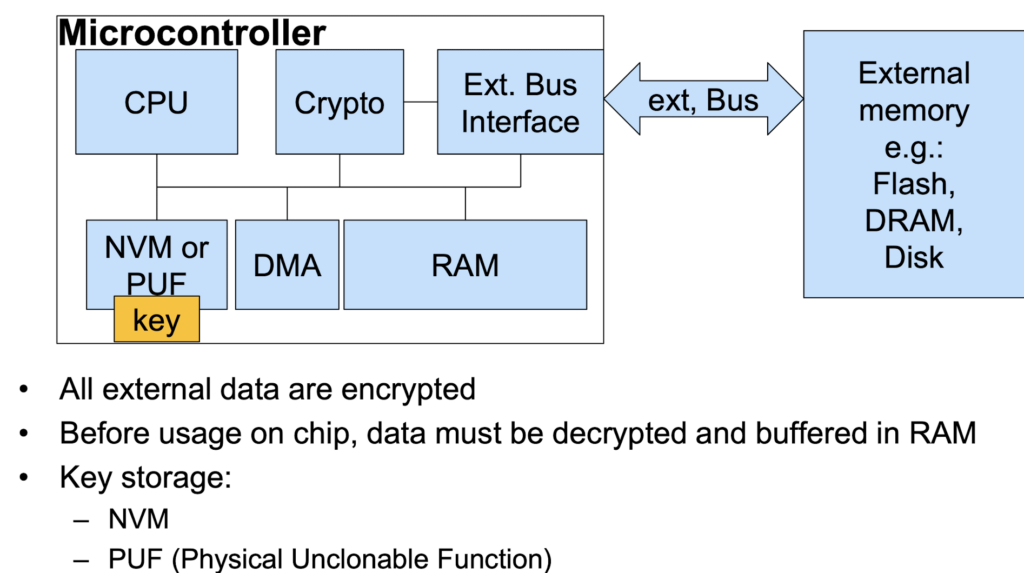
First, DMA transfers external data into the module Crypto, where the data is decrypted. The key is stored in non-volatile memory or obtained by physical unclonable function.
3. Encryption Basics
(1) ECB(electronic code book)
In ECB, all blocks are encrypted independently with the same key. (like looking up a dictionary) Same blocks result in same ciphertext blocks, therefore data patterns in long message are not hidden.
(2) Tweakable Cyphers
Tweakable ciphers are cryptographic algorithms that allow the user to specify a “tweak” value that can be used to modify the encryption or decryption process. The tweak value is typically a small piece of additional input, such as a sequence of bits or a short string, that is combined with the plaintext or key to produce a modified version of the algorithm.
For example, to encrypt Salary, we tweak the employee’s Name:
Encrypt(Name XOR Salary) XOR Name
In this way, we solve the problem in ECB that the same Salary results in the same ciphertext. But we still have a vulnerability in which the attacker can see whether the Salary is changed.
Here are some specific examples of tweakable ciphers where the memory is split into sectors (there may be many blocks in one sector), and same data in different sectors result in different ciphertext.
<1> ESSIV(encrypted salt-sector initialization vector)
- Master key is hashed.
- Sector number is encrypted with hash value.
- But blocks are dependent, which reduces the performance…
<2> XEX
- E_k(i) is derived from sector number, which is the same through n blocks.
- \alpha^j makes X_i,j different for every block.
- BUT, only works well when the size of each sector is a multiple of block size…
<3> XTS (XEX-based)
XTS uses padding, which makes itself works well when sector size is not a multiple of block size.
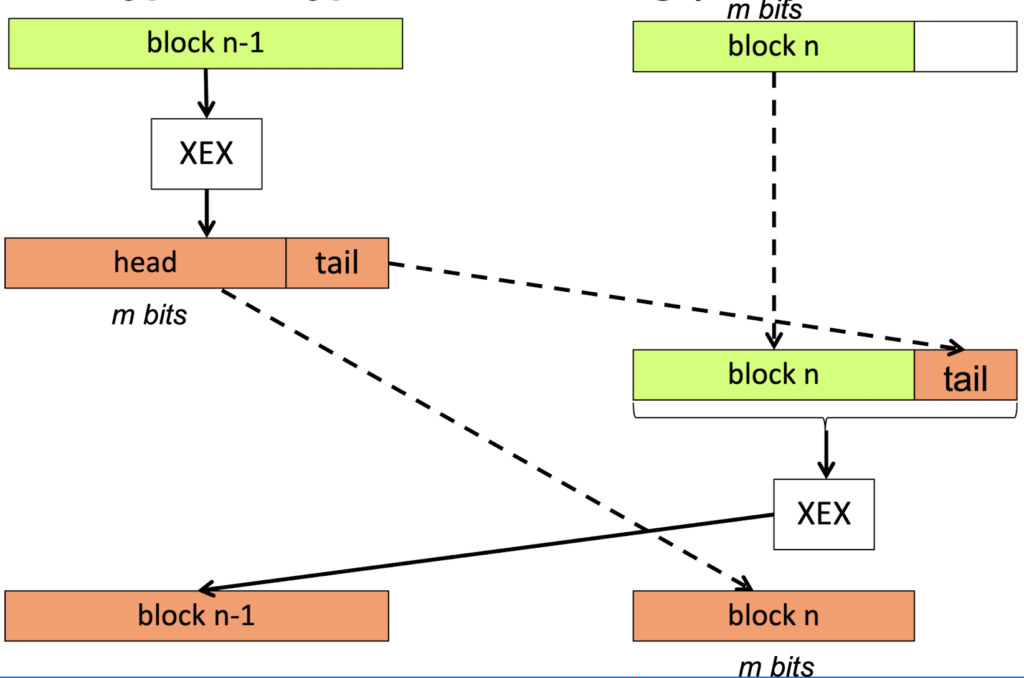
- m < len(block)
- We steal some ciphertext from the last block and pad it to plaintext of block n.
(3) Consequences of external memory encryption
- Latency for external bus accesses increases
Data must be decrypted before usage.
Whole blocks (typically 128 bit) must be read before decryption can start.
If a single bit is changed in a block, the whole block must be encrypted and written back.
- More internal resources needed
More RAM to buffer code (if SW en/decryption is used, the complete software should be buffered).
DMA helps to fetch external data.
- Power consumption is increased.
4. Encrypted Software Updates
(1) CBC mode
- No enough integrity & authentication…
(2) AES CBC-MAC
- Two keys for two encryption: firmware & MAC
- BUT, two times are not efficient…
(3) Authenticated Encryption: GCM
- Integrity: tag would be changed
- Authenticity: only key owner can generate tag
- Confidentiality: encryption using AES-CTR
Chapter 8 Side Channel Attacks
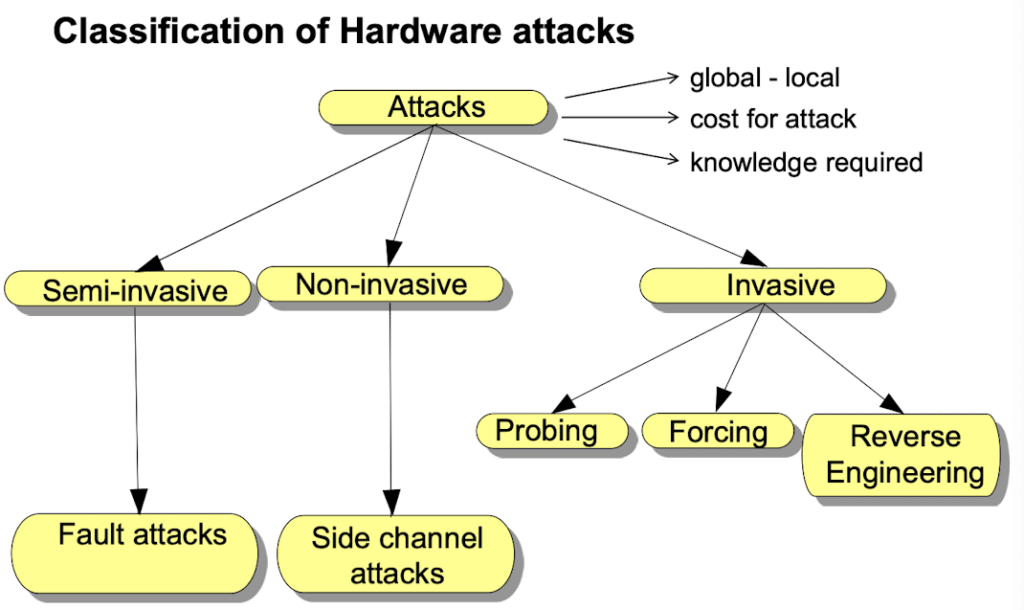
A fault attack is a type of security attack in which an attacker deliberately induces faults or errors in a system in order to compromise its security.
Goals of fault attacks are:
- Bypass password checks (e.g. PIN)
- Overwriting values (e.g. counters or money values)
- Extraction of secrets (e.g. differential fault attacks on RSA or AES)
- No Goal: Destroying the system!
1. Types of Side Channel Attacks
(1) Timing
The attacker uses the differences in processing time to infer information about the system’s internal state or the key.
For example, in AES:
- Timing attack through branches
If-statements in xtime, loops depending on key
- Timing attack through cached memory access
SubBytes table lookups, T-tables
(2) Power
- Differential power analysis (mostly on symmetric cyphers)
The attacker measures a system’s power consumption while performing a set of operations, such as encryption or decryption, and compares the power consumption between two or more operations. (correlation).
For example, differential power analysis on AES.
- Simple power analysis (mostly on asymmetric cyphers)
The attacker measures the power consumption of a system while it performs a single operation, such as encryption or decryption, and uses power consumption results to infer information about the system’s internal state or the key.
For example, simple power analysis on Square and Multiply Algorithm
(3) Radiation
Signal level reveals whether registers are used.
2. Caches and MMU based attacks
- Time driven
An attacker is able to measure time over complete encryptions and builds a timing profile with a known key.
- Access driven
Flush+Reload. If time is short, victim process has accessed data in meantime
- Trace driven
An attacker observes the timing behavior of a processor. Timing is different if cache hits or misses occur. An attacker can infer which locations are stored in the cache memory and which ones are not.
Chapter 9 Trusted Computing
TPM and DICE are both based on asymmetric cryptography based on RSA and Certificates / Challenge Response Protocol.
- TPM
a dedicated Hardware security processor using HW separation
- DICE
low cost software using temporal separation
1. DICE
- UDS (unique device secret)
- DICE Boot Code (root of trust)
- KDF (key derivation function)
- k0=CDI (compound device identifier)